
Harnessing the Power of Generative AI: A Primer to the Action-Brain-Context (ABC) Triangle for LLMs and the Ongoing Evolution of Prompt Engineering and Autonomous AI Agents
Delving into the practical application of GPT Large Language Models (LLMs), this article introduces the Action-Brain-Context (ABC) triangle, leveraging it as a framework to explore the ongoing evolution of prompt engineering and the progressive emergence of autonomous AI agents.


Introduction
In our previous article, we discussed what Generative Pretrained Transformer (GPT) Large Language Models (LLMs) are and the process to create those models. As we continue our journey, our attention shifts towards their practical application – how can we optimize our interactions with these models to realize maximum value?
In a model like ChatGPT, interacting seems deceptively simple; we pose a question and receive an answer. However, crafting the perfect query or 'prompt' and obtaining high-quality responses is an art in itself. This skill has been encapsulated in a new discipline known as 'Prompt Engineering,' where the aim is to devise effective input strategies that elicit desired outputs from the model.
The evolution of prompt engineering has also ushered in a new era of autonomous agents – intelligent entities powered by LLMs and capable of performing tasks independently. This advance pushes the boundaries of LLM applications and brings us a step closer to the potential of Artificial General Intelligence (AGI).
In this article, we introduce a simple yet robust framework for understanding interactions with LLMs – the Action-Brain-Context (ABC) triangle. Using it as a guiding light, we examine the ongoing evolution of prompt engineering and the progressive emergence of autonomous AI agents.
Basic Concepts
Let's start with a crucial concept - prompt. In essence, a 'prompt' is a query or instruction given to the LLM, guiding its response. The nuances of prompt construction are key for effective interaction with the model. A basic form of prompting is illustrated in the figure below.

This prompt example serves as a springboard to several additional notions:
- Samples: A 'Sample' in this prompt example embodies a Question-Answer pair used as a template to guide the model's responses. The number of samples we provide varies with the complexity of the interaction. We can employ several, one, or no samples at all, leading to 'few-shot,' 'one-shot,' and 'zero-shot' prompts, respectively. The art of choosing the right number and type of samples is part of prompt engineering, affecting the quality and specificity of the model's responses.
- In-Context Learning: When we furnish samples, the LLM gleans from these contexts in real-time during a specific query session, an inference stage where the model generates output based on our input. This mode of learning, known as 'in-context learning,' contrasts with learning during pre-training and fine-tuning that we discussed in our prior article. While in-context learning is ephemeral and precise, usually valid only for the current query session, learning during pre-training and fine-tuning is broader and more permanent, influencing all subsequent query sessions.
- Agents: Here, an 'Agent' denotes an AI-based entity working on our behalf. An agent can carry out tasks ranging from answering questions to undertaking more sophisticated functions, paving the way to expanding LLMs' horizons, a thrilling prospect we'll delve into later.
Equipped with an understanding of these foundational concepts, let’s continue to finish inspecting the above prompt example. After the first question and answer sample, we provide the second question without an answer, because we expect our AI agent to give us the answer.
So how did our agent do? Unfortunately, in this case, as we see from the model output, the model got an answer of "27", which is wrong. Why does the AI agent not get it and how can we improve it?
The Action-Brain-Context (ABC) Triangle for Large Language Model Applications
Before delving deeper into the performance of LLM agents, we present the Action-Brain-Context (ABC) triangle, a simple blueprint guiding our discussion on follow-on topics such as prompt engineering and autonomous agents.
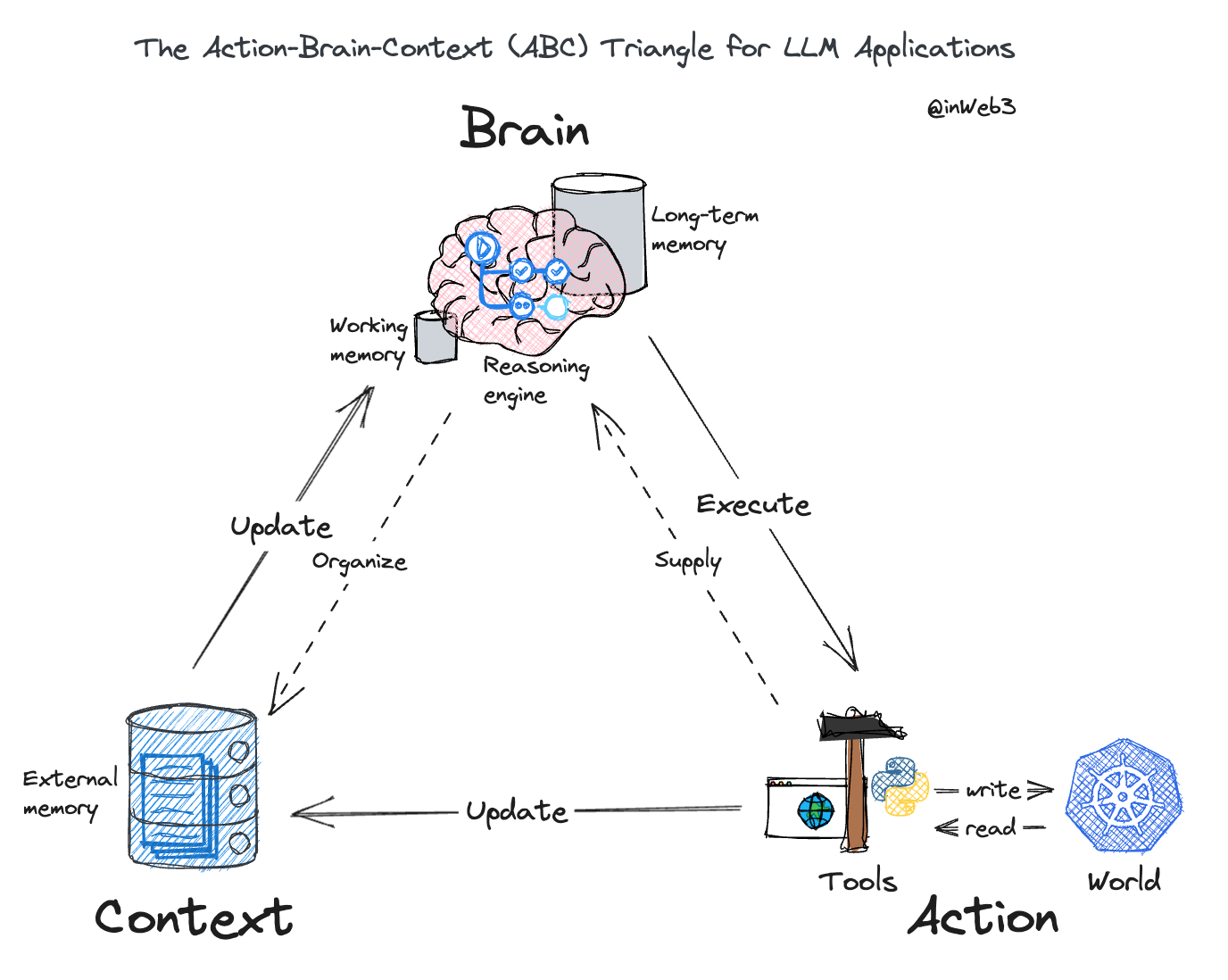
This visual tool provides a high-level overview of the key elements in LLM applications that constitute the interaction with LLMs. Now, let's dissect each component to understand their specific roles and interdependencies. We will go through the sequence of Brain, Context, and Action.
Deciphering the 'Brain'
In the ABC triangle, the 'Brain' represents the core of the system - the Large Language Model itself. This reasoning engine is complemented by two distinctive types of memories - long-term and short-term.
The long-term memory of the LLM encapsulates all the parameters, signifying the knowledge gained during its training phase. In contrast, the short-term memory, also known as the 'working memory' or 'context window,' is capable of receiving real-time information during user interactions. This temporary storage holds the potential to transform the way we interact with these models, allowing a higher degree of responsiveness and adaptability.
Understanding the 'Context'
The 'Context' within the ABC triangle refers to the set of all relevant information related to the query or problem at hand. Given the finite capacity of the LLM's working memory, some context information is stored externally and selectively injected into the working memory when needed.
Context in this triangle bifurcates into:
- Meta Context: examples include direct system prompts ensuring safety and appropriate response structures, as well as desired output format guidelines.
- Dynamic Internal Context: This contains self-reflected intermediate thoughts, for instance, when the LLM uses a step-by-step reasoning approach.
- Dynamic External Context: This includes direct input questions, direct input questions with few-shot examples, and context information obtained through external retrieval.
Defining 'Action'
In our ABC triangle, 'Action' signifies the tasks executed by the LLM through the utilization of tools. While the LLM 'Brain' can achieve some tasks through 'thinking', most complex tasks require 'doing.' Here, performing actions via tools provides the LLM with a medium to interact with the real world.
Knowledge about these tools, like all other knowledge, can either be acquired during the training phase or more commonly, during the usage phase by incorporating tool information as part of the supplying context.
These tools can interact with the external world in two ways:
- Reading: Retrieval augmentation for context involves either searching for additional information online or compensating for specific skills where the model may lack expertise. For instance, using a calculator tool for computations.
- Writing: Actuation control involves using tools to change real-world states, such as sending tweets, booking flights, or making online purchases through specific APIs.
This ABC triangle, with its interconnected components of Action, Brain, and Context, provides a robust scaffold for further exploration into the world of LLM applications.
The Evolution of Prompt Engineering and Autonomous AI Agents: A Multifaceted Perspective
Recall our previous endeavor to enhance our agent's performance in the standard prompt example. Utilizing the ABC triangle, we can accomplish this by concentrating on two pivotal aspects: refining the reasoning methodology and optimizing the working memory context. These crucial components amplify the in-context learning capacities of LLMs, fueling the evolution of prompt engineering methodologies. Consequently, these advancements catalyze the progression of autonomous AI agents.
Chain-of-Thought: Transitioning from Single to Multistep Thinking
When humans approach complex problems, we seldom arrive at a solution instantaneously. Instead, we decompose the problem into manageable steps and proceed sequentially. Can we instill this same logical process in our AI agents?
The affirmative response introduces us to the secret behind 'Chain-of-Thought' prompting, realized through 'in-context learning', as shown below for the same example that our agent failed earlier.
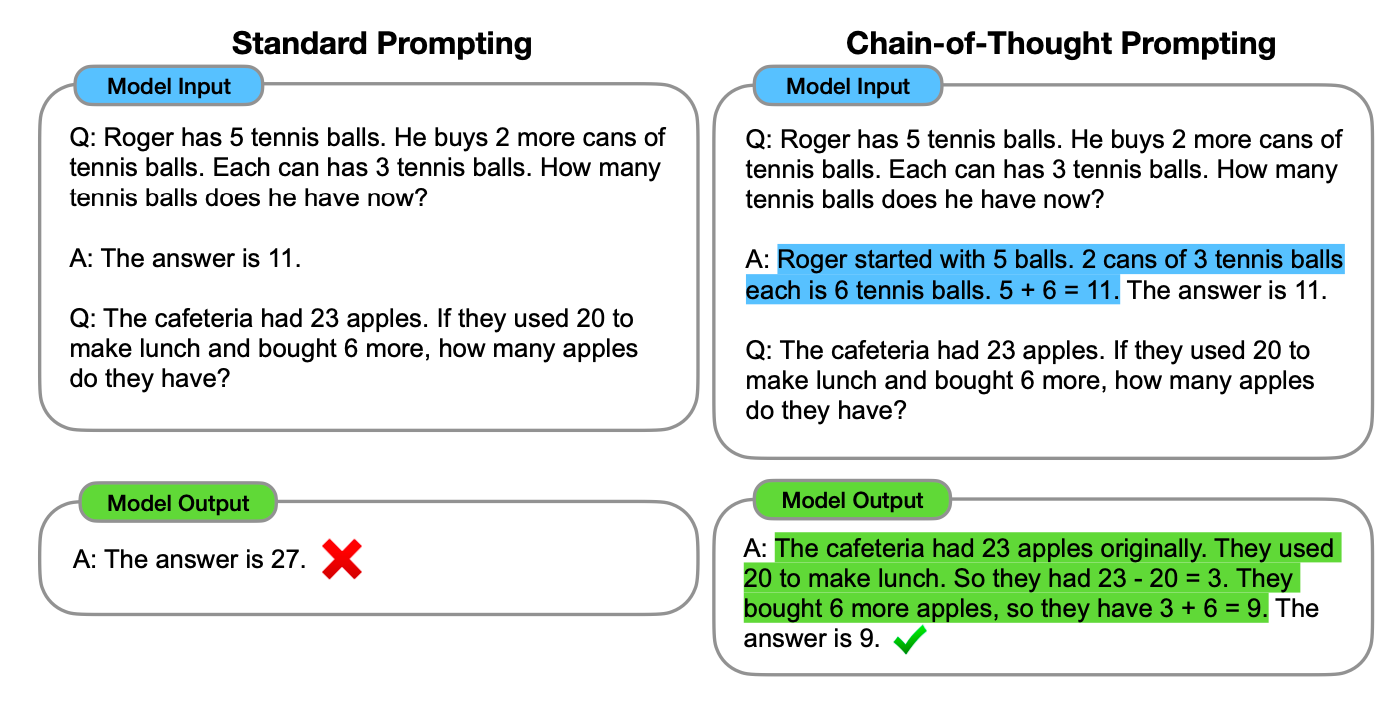
In this approach, we still present a sample question and its response. However, the answer encapsulates not just the conclusion but also the reasoning behind it. This allows the AI agent to learn to incorporate the reasoning step as well. By examining the model output, we find that the model not only provides the final answer but also unveils the underlying thought process.
Even in a zero-shot prompting scenario where no examples are given, the agent can still implement this 'chain-of-thought' approach by adding something like 'please think step-by-step' following the question prompt.
Tree of Thoughts: From Sequential to Parallel Steps
While the 'Chain-of-Thought' typically implies a linear breakdown of problem-solving steps, it doesn't restrict us to this form. The model can create multiple thought processes for the same problem simultaneously, and evaluate the results to pick the majority result as the final answer. This is known as 'Chain-of-thoughts with Self Consistency' (CoT-SC). Furthermore, we can create a tree structure, such that each intermediate thought process can also branch out to multiple child thoughts, and allow a systematic exploration and evaluation of 'Tree of Thoughts.'
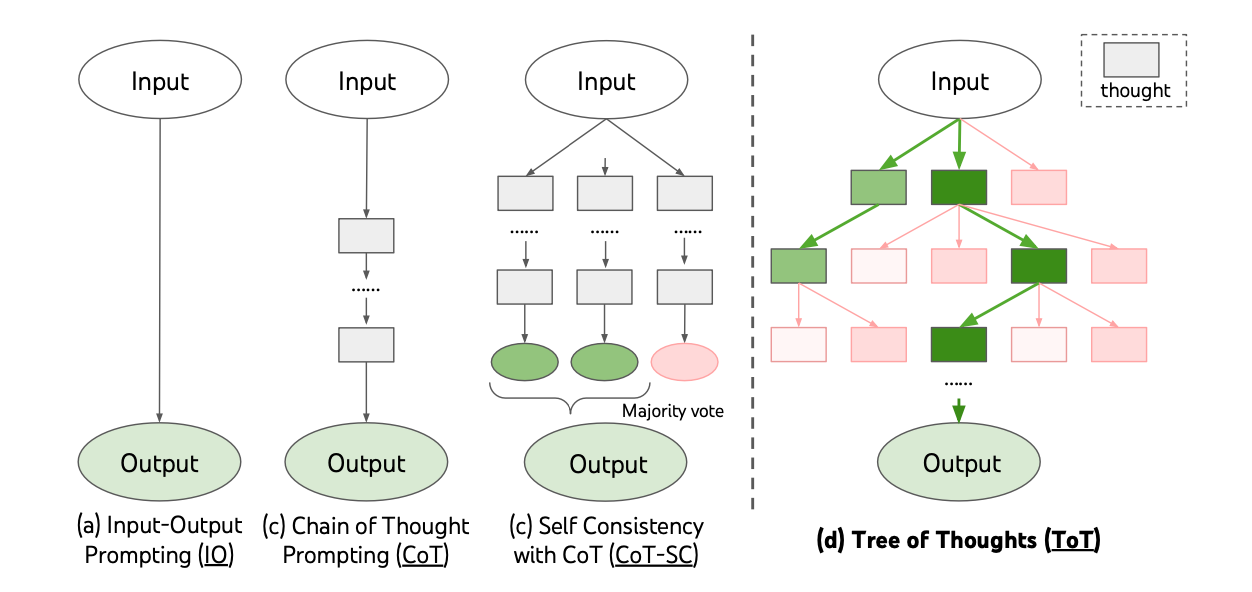
This layered thinking approach mimics human problem-solving methods, offering another stride in prompt engineering.
The Expansion from Pure Thoughts to Actions Via Tools
Now, our agent has become proficient at problem-solving due to its ability to think sequentially and in parallel. However, so far, our approach to problem-solving has been akin to a closed-book exam. Essentially, the agent must answer all the questions based solely on its training, relying on its long-term memory and reasoning capabilities. However, long-term memory isn't always reliable; the agent might have forgotten certain things it learned or jumbled different concepts together. Moreover, it doesn't know anything that occurred after its training data cut-off because it lacks internet access or any other tools for acquiring updated information. Consequently, the agent won't be able to answer factual questions accurately if it does not have the correct information or if its long-term memory is faulty. This is similar to humans; we can't answer factual questions if we don't know the facts.
However, our agent has an additional drawback: it doesn't usually admit when it doesn't know the answer. Instead, it creates a response, presenting it convincingly with seemingly high confidence. This phenomenon is known as the hallucination problem of LLMs.
How do we mitigate this issue? Let's consider how humans deal with such situations. If we don't know something, we seek more information from the external world using the tools at our disposal, such as browsing the web, using a calculator, writing computer programs, etc. Since our goal is to have our agent correctly execute tasks for us, we need not confine it to a closed-book environment. We can provide our agent with the tools we use and encourage it to utilize them to solve problems. This leads us to another vital aspect of prompt engineering: equipping our agent with tools to interact with the external world and enrich the context for problem-solving. In other words, we're now setting our agent an open-book exam. For instance, it can decide to search the web for up-to-date information (although the accuracy of internet content isn't guaranteed, and if the agent stumbles upon incorrect information, it may still provide incorrect responses). We can also provide the agent with a calculator tool or programming environments (despite the potential security concerns).
A notable prompt technique incorporating this methodology is called ReAct (Reason + Act). In the following example, the prompt enables a series of thoughts accompanied by web search actions. Observations from these actions inform the subsequent thought process.

By augmenting our agent's capabilities with external tools, we open new possibilities for problem-solving that would otherwise be inaccessible.
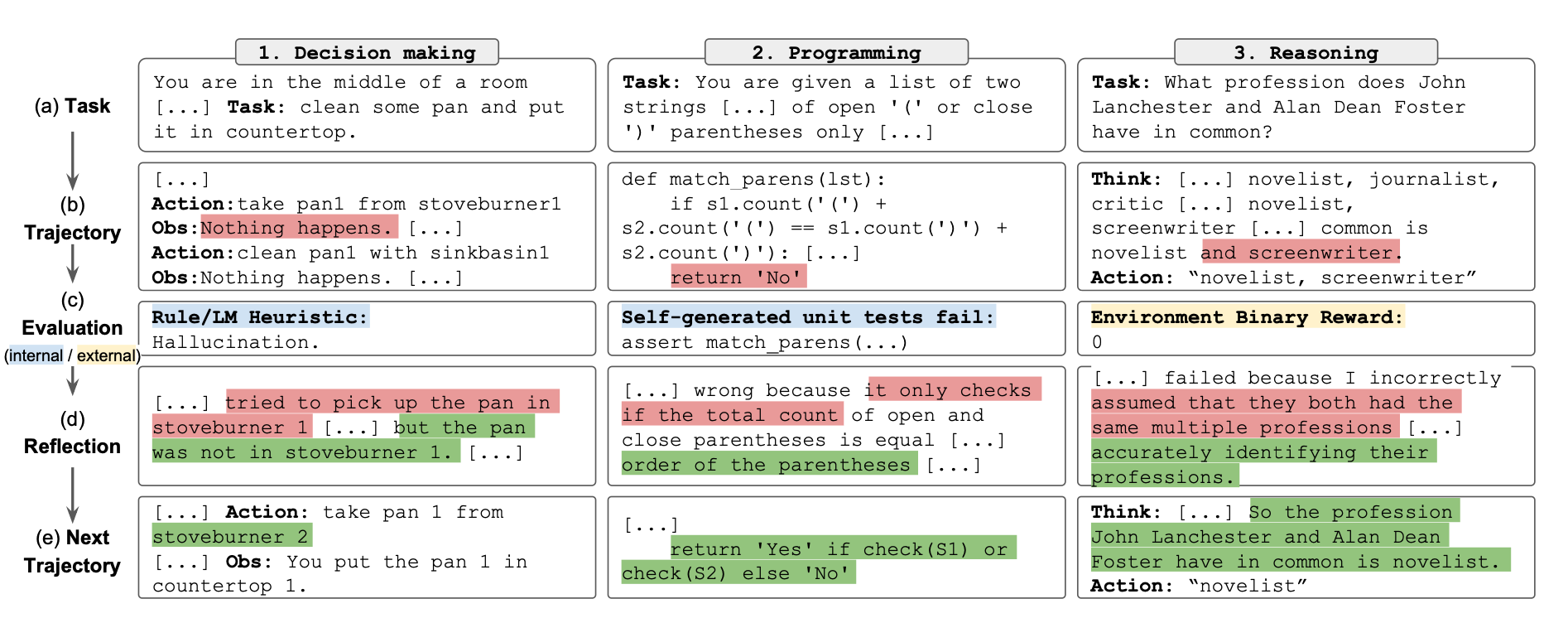
From Actions to Reflexive Actions: Towards More Autonomy
Beyond reasoning and actions, the introduction of self-reflection into the agent's process can elevate its autonomous behavior. As demonstrated by the Reflexion prompting methodology, the model uses reflection to amplify sparse feedback, driving iterative learning and more nuanced responses.
Multi-Agent Autonomous Systems: Collective Problem-Solving
The evolution of prompt engineering has paved the way for advanced autonomous agent architecture. Until now, our agent has been working alone, decomposing problems into manageable steps, both sequentially and in parallel, and utilizing tools provided.
However, even more power of AI lies in its ability to replicate and create a team of specialized sub-agents. These autonomous agents, each proficient in a particular role, can collaborate to potentially solve complex problems. This presents a new frontier for LLM applications.
Two examples of this paradigm are Auto-GPT and Baby-AGI. Below is a flow diagram of Baby-AGI:
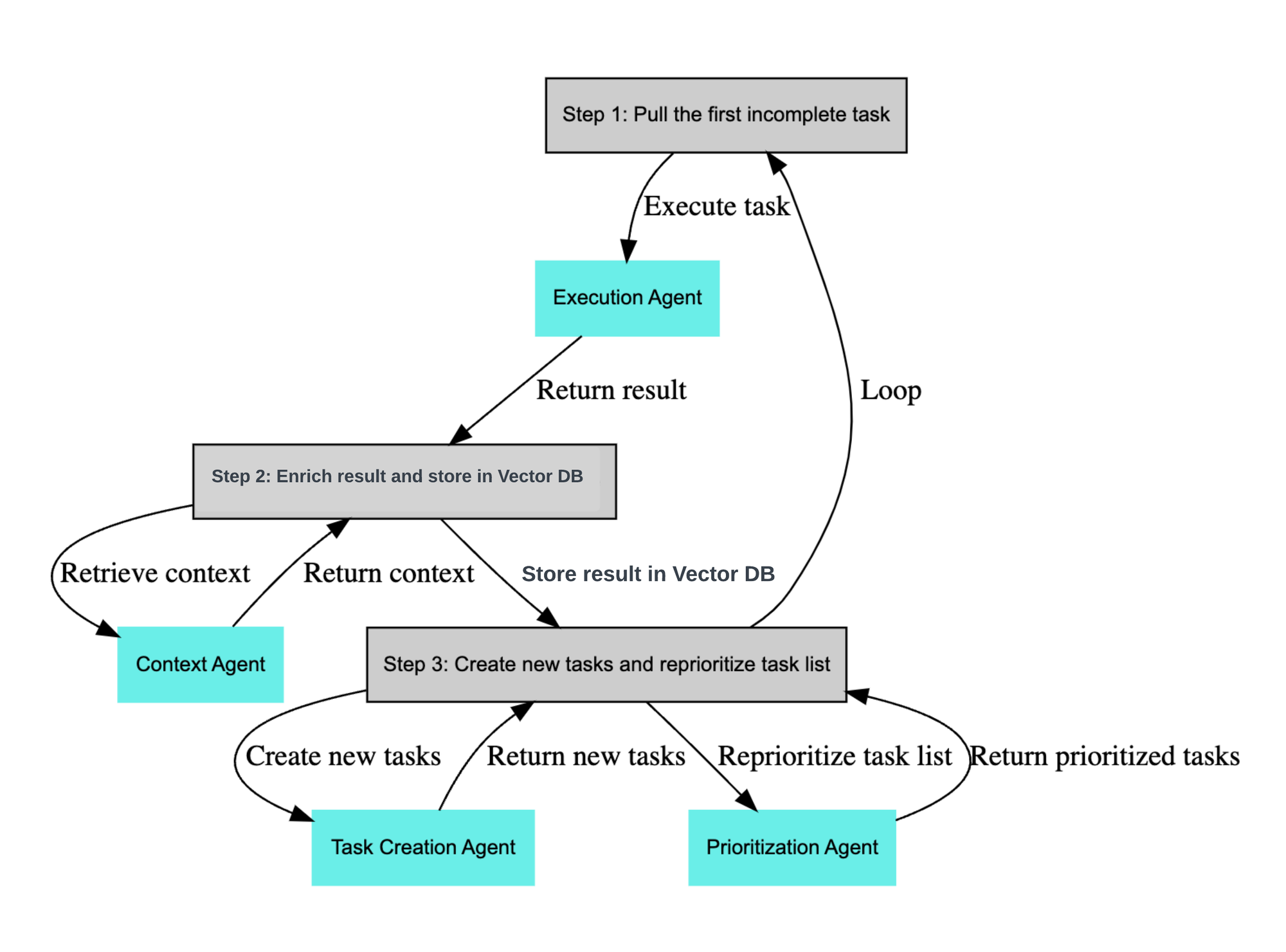
Here, the execution of a task is divided among various specialized sub-agents. After receiving an initial goal, the task creation agent devises a list of tasks towards that goal. Subsequently, the prioritization agent ranks these tasks, and the execution agent performs the most critical ones. A context agent processes the outcomes of these tasks to enrich the project context. This cyclical process continues until the goal is achieved.
Lifelong Learning: From Close-ended Objective to Open-ended Exploration
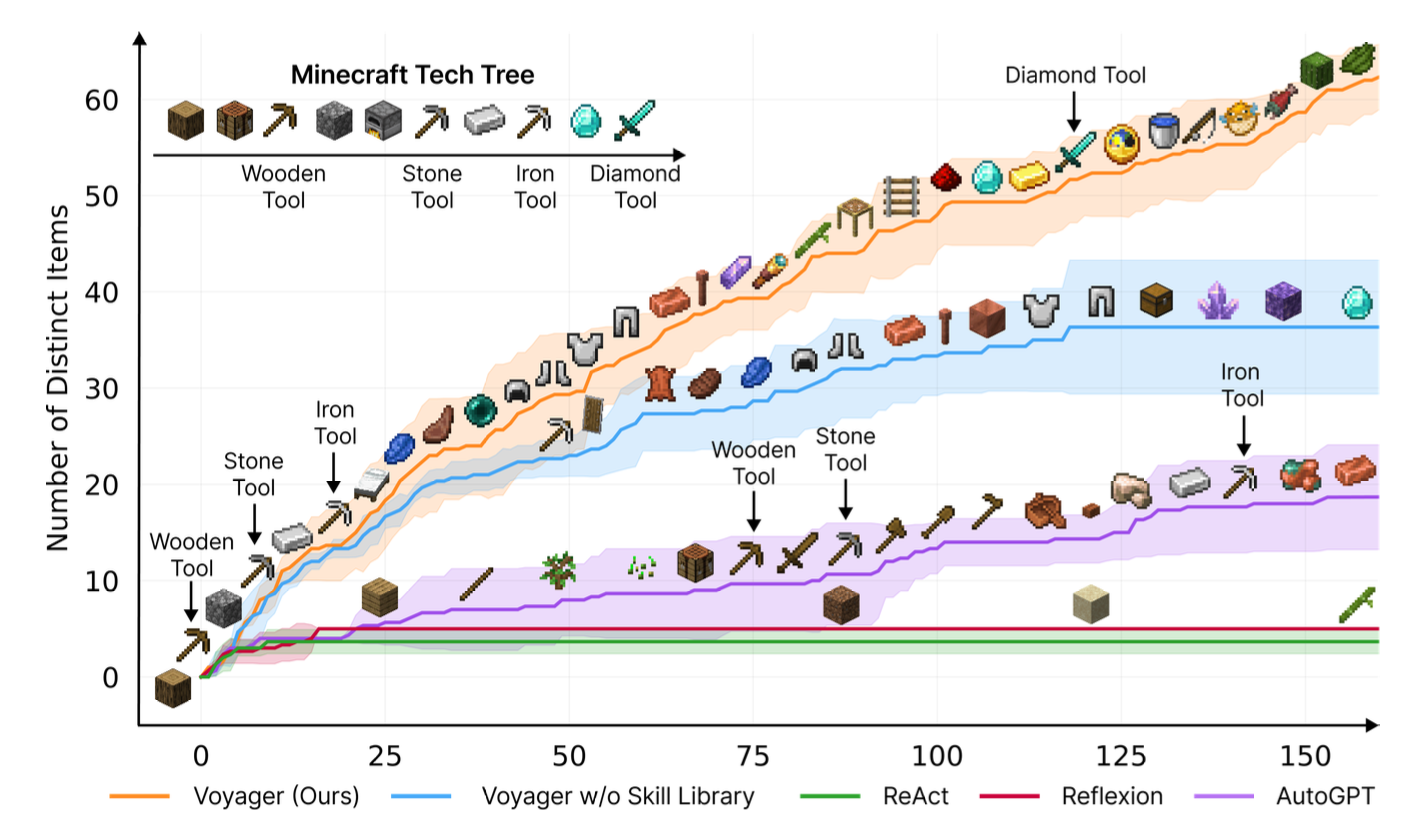
Till now, our AI agent has been working on closed-end problems with a clearly defined objective. However, another exciting task for our agents is to continuously explore and learn in an open-ended environment. In a project called Voyager, researchers developed the first LLM-based embodied lifelong learning agent for Minecraft that outperformed ReAct, Reflexion, and AutoGPT.
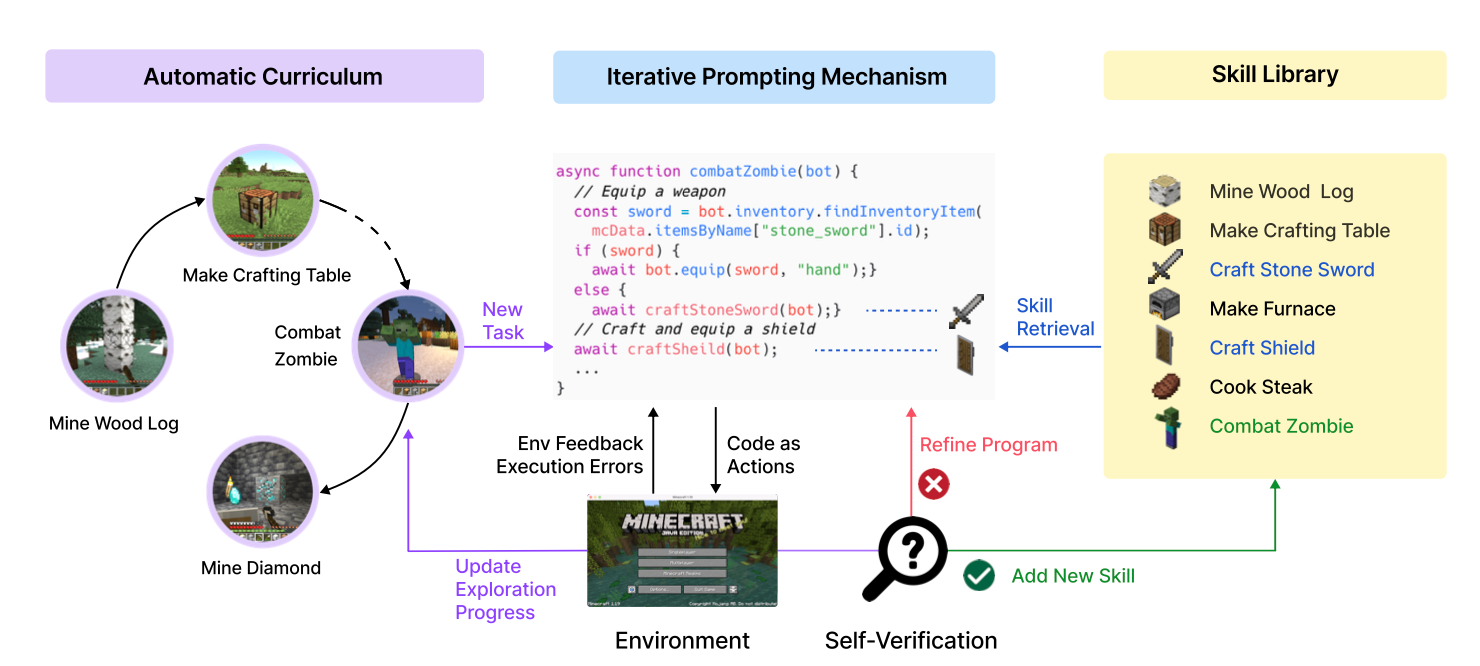
Voyager comprises three key components:
- The Automatic Curriculum, a sub-agent, continuously proposes progressively challenging tasks for open-ended exploration.
- An iterative prompting mechanism generates code to execute actions, functioning as the execution sub-agent.
- A skill library serves as an external context memory that stores complex behavior for future reference.
Social Agents: Individual Traits in Collective Norms
The next frontier in the realm of LLMs lies in developing 'social agents.' These autonomous generative AI agents exhibit social behaviors while developing individual traits within a loosely bound collective norm.
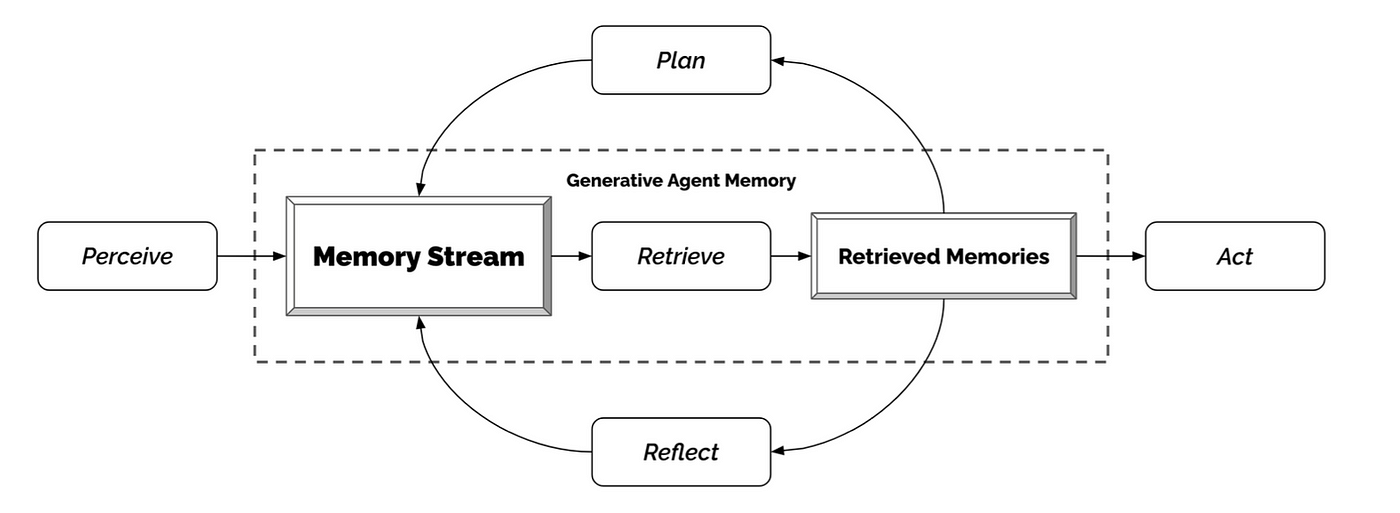
In the Stanford Smallville experiment below, a group of individual generative agents simulate human behavior. Each agent is seeded with unique characteristics such as author, artist, professor, and student. They perform daily activities, form opinions, engage in conversations, and exhibit a sense of past and future.
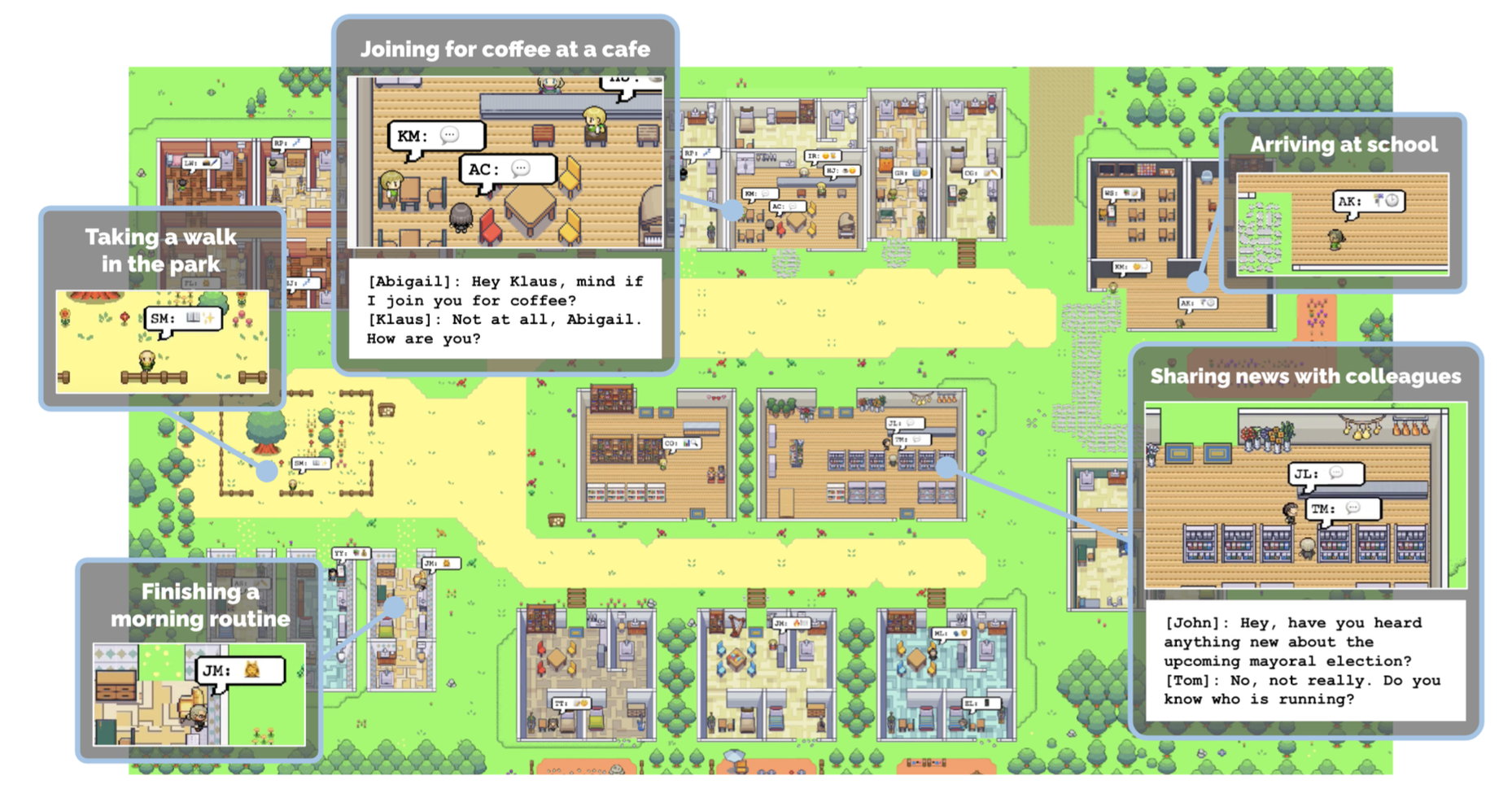
Crucial to creating this social generative agent simulation is how each agent perceives and organizes their context, including interactions with others and self-reflection. This context is stored in external memories and influences the ongoing thoughts and interactions between agents, as depicted in the architecture below:
Evolution Summary
The table below summarizes the key aspects of the various ongoing evolution stages discussed above:
| Name | Multi- step reasoning (sequential / parallel) | Action tools | Multi-agent | Custom context optimization |
|---|---|---|---|---|
| Chain-of-Thought (CoT) | Yes | - | - | - |
| Tree-of-Thought (ToT) | Yes | - | - | - |
| ReAct | Yes | Yes | - | - |
| Reflexion | Yes | Yes | - | - |
| Auto-GPT/Baby-AGI | Yes | Yes | Yes | Yes |
| Voyager | Yes | Yes | Yes | Yes |
| Social generative AI agents | Yes | (Yes) | Yes | Yes |
Conclusion
Guided by the Action-Brain-Context (ABC) triangle as a framework, we examined the evolution of prompt engineering methodologies and autonomous AI agents. From the basic standard reasoning mechanism, we traversed through Chain-of-Thought (CoT) and Tree-of-Thoughts (ToT) methodologies, which respectively introduced multi-step sequential and parallel reasoning.
The ReACT technique and Reflexion extended this evolution by integrating actionable tools and self-reflection into the reasoning process. Auto-GPT and Baby-AGI further expanded these concepts, distributing the reasoning process among multiple autonomous agents working collectively.
Voyager, aiming for lifelong learning in open-ended environments, and generative agents for social behavior experiments, exploring emergent social patterns, both pushed boundaries by further enhanced reasoning and context optimization.
In conclusion, our exploration of the evolution of prompt engineering methodologies and the advancement toward potentially sophisticated, socially-interactive autonomous AI agents highlights the immense potential of contemporary AI technologies. Nevertheless, it is crucial to recognize that the existing autoregressive LLM-based AI approach falls short of the requisites for achieving genuine autonomy in AI, which necessitates further significant breakthroughs.