
Can ChatGPT unlock blockchain data for the masses? Early insights from building ChatWeb3
Introduce ChatWeb3 - a chatbot harnessing ChatGPT for blockchain data analysis. Powered by OpenAI, Langchain, and Flipsidecrypto, we examine its workflow, examples, challenges, and future potential in AI-driven blockchain analytics for all.


Updates on ChatWeb3
- January 2024: the GPT is in the official OpenAI GPT store and can be accessed as the "Blockchain Data Explorer" GPT. Here are two recent sample conversations: Sample 1 on USDe: inspired by this dashborad from Mrfti. Sample 2 on PEPE: more oriented at asking the GPT to come up with follow-up research questions.
- November 2023 : the ChatGPT plugin has been converted to a GPT .
- September 2023: the ChatGPT plugin of ChatWeb3 is released, here is a quick test conversation with it.
- April 2023: original prototype built and article published.
Introduction
The rapid expansion of blockchain technology has created a pressing demand for accessible, user-friendly data analysis tools. Artificial Intelligence (AI), particularly large language models (LLMs) like ChatGPT, offers significant potential for addressing this need. However, there are both advantages and challenges associated with leveraging AI for blockchain and cryptocurrency data analysis.
Just this week, Binance announced a ChatGPT-powered chatbot Sensei for its Academy. This chatbot, trained on over 1000 articles from the academy, is designed to provide educational guidance rather than real-time blockchain data. For instance, when asked a question about the trading volume of a specific token, the chatbot may recommend articles related to "Volume" or "Volume-Weighted Average Price (VWAP)."
In a parallel development, Solana Labs recently released a ChatGPT plugin that enables users to access real-time blockchain data through AI-powered chatbots. According to the screenshot shared on Twitter, the plugin can perform tasks such as retrieving information about the NFTs owned by a specific address. This plugin utilizes APIs from Hyperspace, a comprehensive Solana-based NFT platform.
A more versatile ChatGPT-powered blockchain data access tool could potentially tap into extensive databases hosting various types of blockchain data across multiple chains. Currently, blockchain analysts typically use SQL to query data curated by providers like Dune and Flipsidecrypto. As ChatGPT can transform natural language prompts into SQL, creating a tool that allows users to interact directly with these SQL databases through ChatGPT could democratize blockchain data access. By eliminating the need for specialized programming skills, such as SQL, this tool would enable a much broader audience to conduct blockchain data analytics.
How close are we to realizing this vision? To explore the possibilities and challenges, inWeb3 has been developing ChatWeb3 - a chatbot that people can use to access crypto and Web3 data. In the following sections, we will share preliminary results and insights gleaned from this endeavor.
ChatWeb3 implementation
This section introduces the key components of ChatWeb3, discussing the AI, crypto and blockchain elements, the integration process, and the frontend user interface.
AI: For the AI component, our ChatWeb3 prototype employs OpenAI's gpt-3.5-turbo Large Language Model (LLM). This model offers a favorable balance between capability and cost, as it is considerably more affordable at less than 1/10 the price of the newer GPT-4 model, making it a suitable choice for testing purposes.
Crypto/Blockchain: On the crypto and blockchain side, ChatWeb3 is currently powered by Flipsidecrypto. It houses a vast collection of curated and annotated blockchain data from numerous chains, hosted within Snowflake data warehouses.
Integration: We utilize the Langchain development framework to integrate the AI and crypto components. Specifically, we take advantage of Langchain's SQL toolkit concept and ChatAgent. To ensure compatibility with the database and schema structure of Flipsidecrypto's databases on Snowflake, we made the necessary customizations to the code and prompts.
Frontend: The frontend features a straightforward chat interface hosted on Gradio, which displays both the chat history and the AI's thought process as it answers questions. Given that LLMs like GPT can generate varying solutions (both correct and incorrect) to user queries, it is crucial to examine the intermediate processes—particularly the actual SQL code—during the experiments to verify the output.
How does a query flow in ChatWeb3 work?
The following section describes the query flow in ChatWeb3, detailing the communication process between different entities, including the ChatWeb3 agent, GPT, and the databases. This system is designed to facilitate seamless interactions between the user, AI, and blockchain data.
Consider a user who submits a question to ChatWeb3, here is a list of what happens next.
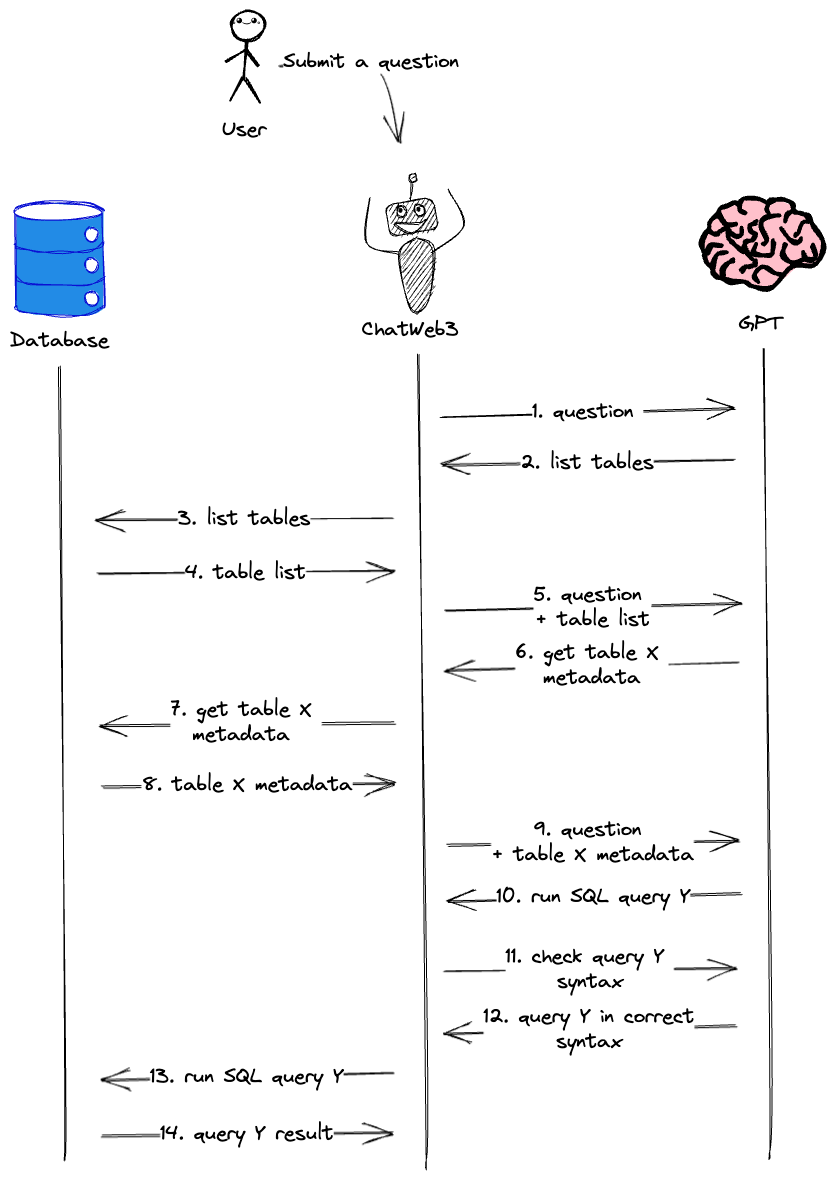
- The ChatWeb3 agent receives the user's question and submits it to GPT for further instructions.
- GPT responds by requesting the agent to query the database for available tables.
- The agent runs a database query to retrieve table information.
- The database returns the table information to the agent.
- The agent submits the table info to GPT, along with the original user question.
- GPT examines the available table information and selects the table most relevant to the user's question. It then asks the agent to check the metadata for that specific table.
- The agent requests the metadata for the specified table from the database.
- The database returns the table metadata to the agent.
- The agent submits the table metadata to GPT, along with all prior communications.
- GPT constructs a syntactically correct SQL query for the original question and instructs the agent to execute it against the database.
- Before running the query, the agent double-checks the SQL syntax with GPT for accuracy (only providing the candidate SQL query).
- GPT confirms the SQL query is syntactically correct or provides its corrected version.
- Once the agent receives the confirmed SQL query, it proceeds to run the query against the database.
- The database returns the query results to the agent.
After obtaining the results, the agent can either immediately present the information to the user or, optionally, submit the raw result to GPT for formatting a more descriptive final output. In case of an error during the query process, the agent will re-check the SQL syntax and retry the corrected query.
The roles of GPT in ChatWeb3
The SQL Toolkit
Let's delve deeper into the roles of GPT within ChatWeb3. The Langchain SQL toolkit equips GPT with four specific tools that serve different purposes via its prompts. These tools include:
- list_table_tool: Lists all available tables.
- get_table_info_tool: Retrieves metadata for given tables, such as column and sample row information.
- query_database_tool: Submits a SQL query to the database and obtains results.
- check_sql_syntax_tool: Checks the syntax correctness of a SQL statement.
The first three tools interact with the database system to retrieve information, while the fourth tool is a separate call to GPT purely for checking SQL syntax, without accessing the database.
The specific tools in our case are the following (which are customized from Langchain's default tools):
check_available_tables_summary:
Input is an empty string.
Output is the list of available tables in their full names (database.schema.table), accompanied by their summary descriptions to help you understand what each table is about.check_table_metadata_details:
Input is one or more table names specified in their full names (database.schema.table) and seperated by a COMMA.
Output is the detailed metadata including column specifics of those tables so that you can construct SQL query to them.check_snowflake_query_syntax:
Input is a Snowflake SQL query.
Output is the syntax check result of the query.query_snowflake_database:
Input to this tool contains a Snowflake SQL query in correct syntax. It should be in JSON format with EXACTLY ONE key "query" that has the value of the query string.
Output is the query result from the database.
The primary role of GPT is to determine the next action to take (i.e., which of the four tools above should be used next) and how to take that action (i.e., generate the appropriate inputs necessary to execute the selected tool).
Checking and selecting the table
When presented a question, the GPT is first instructed to always start by selecting the list_table_tool that checks all the available tables in the database. Today's LLMs like ChatGPT is notoriously prone to hallucinating their responses. Without this specification, the GPT model will happily "invent" some non-existing table and columns to form an invalid SQL query. In this step, the input to the tool is empty, which instructs the agent to retrieve all tables available. Once it receives the list of tables, the GPT needs to make a decision on which table to query. Here's the actual prompt:
You MUST always start with the check_available_tables_summary tool to check the available tables in the databases, and make selection of one or multiple tables you want to work with if applicable.
This step has an important trade-off to make. A default option is to provide GPT the names of all the tables in the database. In many cases, purely a table name doesn't have sufficient information and could lead to poor table choices. Since most of Flipsidecypto's tables come with a comment column, we augmented the table names with a brief description drawn from the table comment. We have seen the inclusion of table description improving the performance of table selection when a large number of tables are enabled.
However, adding descriptions affect the number of words, or more precisely, language tokens that we put into the prompt window of GPT. OpenAI has a rule-of-thumb of roughly 4 English characters per token. The 'gpt-3.5-turbo' model we use has a maximum token size of 4K. This limit includes both the question input part and the response output part. When we add more content to the table description, it takes up more space of the overall token window. What makes it worse is that, this content accumulates in the prompt window. As we go through multiple steps, each steps' inputs and outputs stacks together in the prompt window to give later GPT queries a better understanding of the entire thought process. But this practice also squeezes the prompt size. For this reason, we only enabled a small number of representative tables from Flipsidecrypto's Ethereum database when performing the sample tests here, specifically, the tables are "ethereum.core.ez_dex_swaps", "ethereum.core.ez_current_balances", "ethereum.core.ez_token_transfers", and "ethereum.core.dim_labels". But even with this list of tables, we still frequently see GPT making different choices among "ez_dex_swaps", "ez_token_transfers", "ez_current_balances" when we are asking about token trading or balance information. These tables often contain inter-related information and the choices may or may not lead to wrong results.
Creating a SQL query to the selected table with correct syntax
Once the table is chosen, GPT needs to formulate a correct SQL query and return it to chatbot, which will submit the query to the database. To avoid hallucination, GPT is instructed to always check the metadata of the table before creating a query for it, with the following prompt:
If you need to construct any SQL query for any table, you MUST always use the check_table_metadata_details tool to check the metadata detail of the table before you can create a query for that table. Note that you can check the metadata details of multiple tables at the same time.
In our tests, this prompt largely prevents GPT from making up columns without even looking at the table information. However, when things gets more complicated, e.g., when it decides to create join statement with two tables, it starts to forget it, requests only one table and then make up the other table or columns. We can of course further revise the prompts to address these issues. But the caveat is that it's not easy to cover all cases, and longer prompts again squeezes the space of the limited overall prompt window.
The prompt size is also a consideration here when we select what table metadata to include and how to present them while saving space. We customized this information by including the column comments from Flipsidecrypto database along with the column types and three sample values for each column.
Double checking the validity of a SQL query
When GPT generates a SQL query and returns it to the agent for execution, it's common practice to perform another GPT query to double-check the query syntax. In our case, we found that this may not always be necessary and decided not to emphasize it in the prompt for several reasons:
- Skipping this step saves prompt space by reducing the roundtrip of message exchanges.
- We noticed instances where the check_SQL_syntax_tool reports the query as valid, but the query fails. This is usually because GPT generates syntactically correct SQL statements with invented tables or columns. Since the check_SQL_syntax_tool does not have information about actual tables and columns in the database, it can't accurately verify the query's validity.
Therefore, we also adjust the error handling prompt to include the cases where the error is not caused by pure syntax problems. This part of the prompt is as follows:
If you receive and error from query_snowflake_database tool, you MUST always analyze the error message and determine how to resolve it. If it is a general syntax error, you MUST use the check_snowflake_query_syntax tool to double check the query before you can run it again through the query_snowflake_database tool. If it is due to invalid table or column names, you MUST double check the check_table_metadata_details tool and re-construct the query accordingly.
However, with the current setting and overall prompt size, there is often not enough space for additional rounds of interaction in case of error. The table re-selection part of the prompt will need to be tested in future versions.
Exploring a simple question-response example with ChatWeb3
Let's examine a simple question-response example using ChatWeb3:
What is the total daily trading volume in USD on Uniswap in the last 7 days?
Below are the outputs:

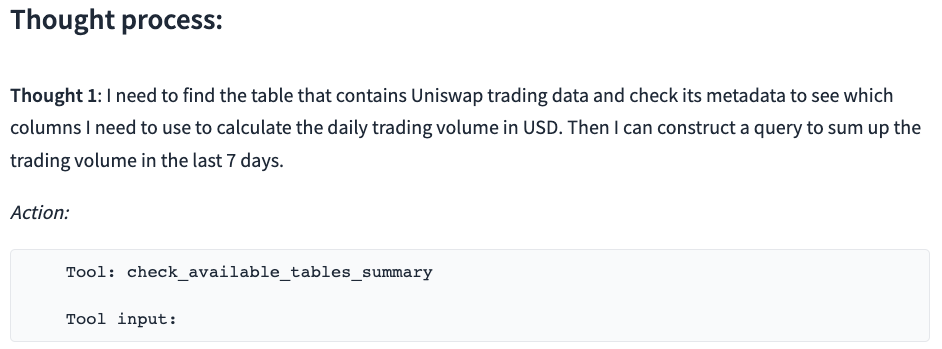
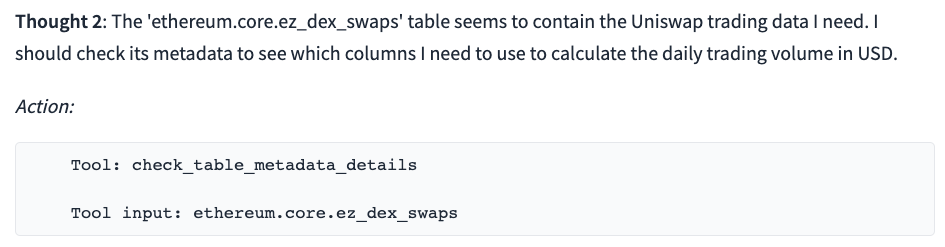
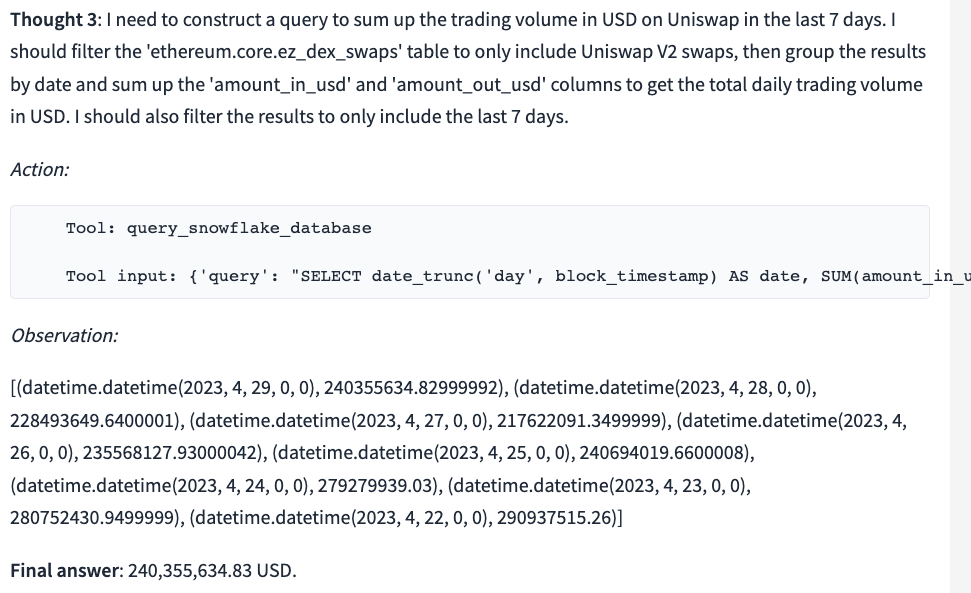
The ChatWeb3 output demonstrates that GPT first asks for the list of tables and then correctly selects the ez_dex_swaps table from the list. It also constructs a syntactically correct and meaningful SQL query.
SELECT date_trunc('day', block_timestamp) AS date,
SUM(amount_in_usd) + SUM(amount_out_usd) AS total_volume_usd
FROM ethereum.core.ez_dex_swaps
WHERE platform = 'uniswap-v2'
AND date_trunc('day', block_timestamp) >= DATEADD(day, -7, CURRENT_DATE())
GROUP BY date ORDER BY date DESCHowever, the calculation of daily trading volume using SUM(amount_in_usd + amount_out_usd) could be considered double-counting, as both amounts represent tokens involved in the swap, converted to USD using the token price. This is a subtle issue that frequently occurs in our experiments, where GPT's interpretation of language input might deviate from the original intended meaning.
This example highlights the importance of verifying the underlying SQL statement, which could undermine the value proposition of this approach since users would still need to understand SQL. In some cases, GPT constructs complex queries for seemingly simple but ambiguous prompts, requiring users to have a solid knowledge of SQL to judge the validity of the response. Therefore, at this stage, GPT serves more as a co-pilot or assistant rather than a fully autonomous tool. This may be true for many other AI use cases as well.
To correct this issue, we can make the prompt more explicit by adding (only count one side of the trading amount) to the question:

We can now verify that the underlying SQL counts only the amount_in_usd as expected.
SELECT date_trunc('day', block_timestamp) AS date,
SUM(amount_in_usd) AS total_volume
FROM ethereum.core.ez_dex_swaps
WHERE platform = 'uniswap-v2'
AND date >= DATEADD(day, -7, CURRENT_DATE())
GROUP BY date ORDER BY date DESC
This example also demonstrates the importance of Prompt Engineering, a process used to improve GPT's reasoning by providing appropriate prompts and achieving the desired results despite its limitations.
A more detailed case study
Author's note: Though this section benefits from basic SQL knowledge, you can still grasp the main ideas even if you skim over the specific SQL statements.
Now that we have gained a deeper understanding of how ChatWeb3 functions, let us explore a more realistic and entertaining example to assess whether it can assist us in our blockchain data analysis efforts.
Meme coins are a type of cryptocurrency that gained popularity through their association with internet memes. Their market sentiment is often driven by these memes, which in turn influences their speculative token values. Dogecoin is the most well-known meme coin, but the latest meme coin craze revolves around a token called PEPE. This token, inspired by the "Pepe the Frog" internet meme and launched in mid-April 2023, even turned someone's $250 into more than $1M in just four days (although liquidity constraints prevented the investor from cashing out the profit). Let's examine this PEPE coin more closely.
We will use a $PEPE Analysis dashboard on Flipsidecrypto, created by @Mrftio, as a reference point to see if our crypto chatbot can replicate its analysis. The original dashboard is divided into an overview section and a trading analysis section, each containing several subcategories.
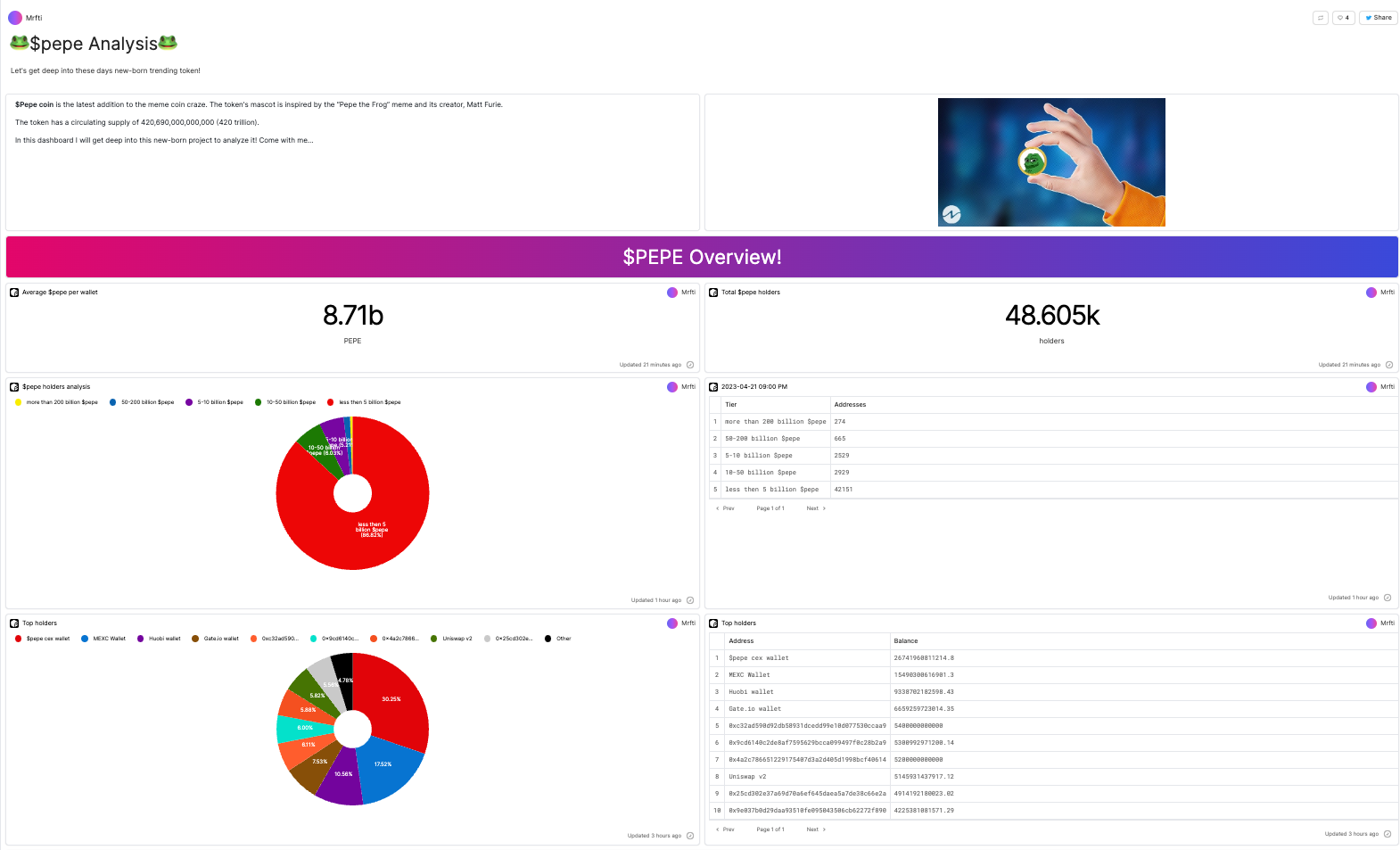
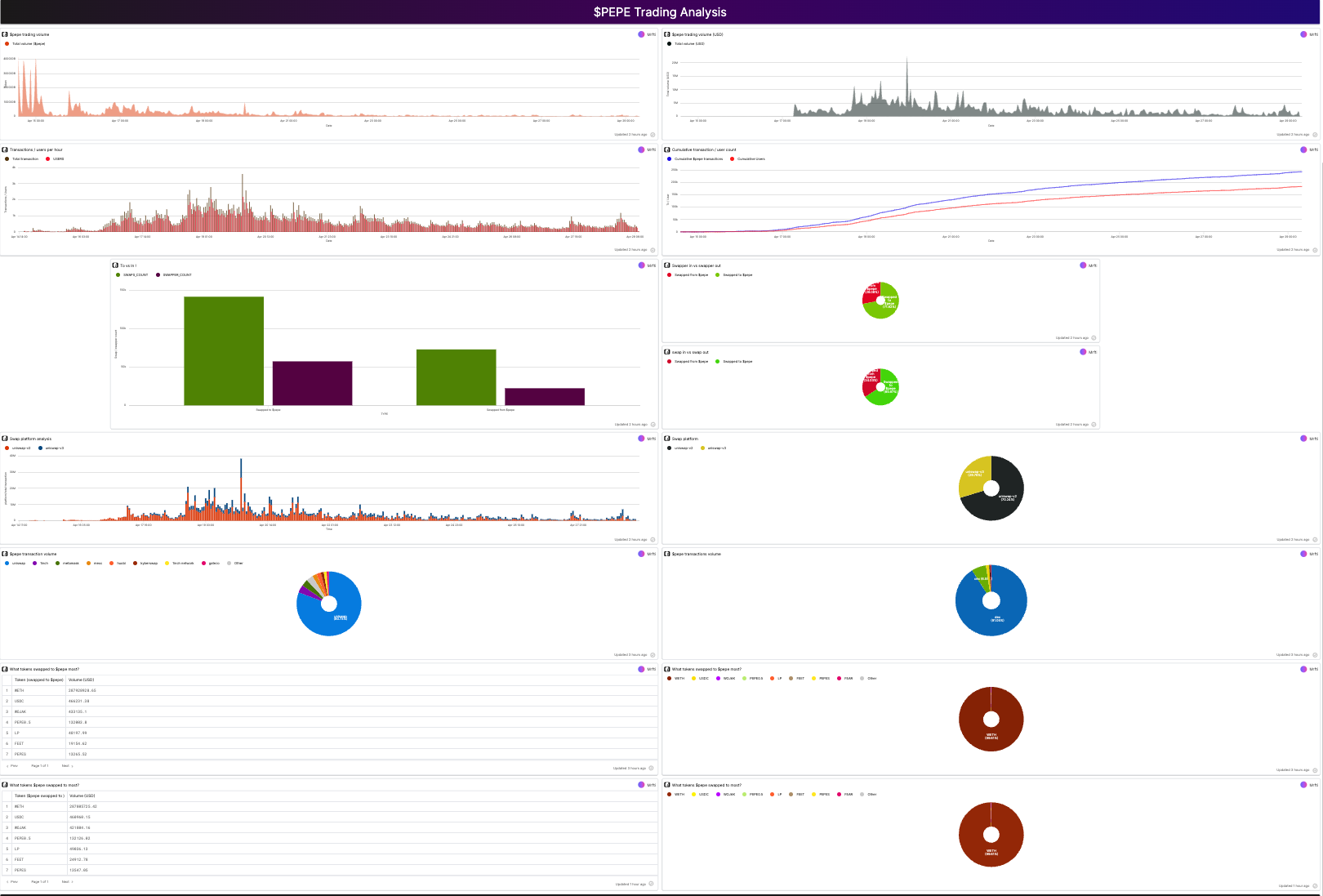
Note that our current chatbot does not generate visualizations, so we will only evaluate its ability to produce similar text results.
Number of token holders and average tokens per-wallet analysis
The analysis begins by determining the number of wallet addresses holding the PEPE token and the average number of tokens per address. We posed the following question to the chatbot:
Prompt A: PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the number of PEPE token holders and what is the average token balance per holder?
It is crucial to provide the chatbot with the token's actual address, as the mapping of addresses to token symbols is not unique, and both legitimate users and scammers can create tokens with the same symbols. In fact, we added the following to the GPT instruction prompt to make it aware.
When constructing a query containing a token or NFT, if you have both its address and and its symbol, you MUST always prefer using the token address over the token symbol since token symbols are often not unique.
We also need to use the lowercase version of the address, as required by the database. These considerations apply equally to users who construct their SQL queries directly.
The chatbot's response was as follows:

But is that correct? Let's look at the SQL query it produces:
SELECT COUNT(DISTINCT to_address) AS num_holders,
SUM(amount)/COUNT(DISTINCT to_address) AS avg_balance
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
AND has_decimal = 'true'
AND has_price = 'true'
AND amount IS NOT NULL
AND amount_usd IS NOT NULLThe GPT selected the ez_token_transfers table to count the number of people who have received the token, considering them as holders. This approach differs from the original dashboard, which uses the ez_current_balances table to count those who actually hold a current token balance. This discrepancy demonstrates how GPT's interpretation of our question may vary. However, one could argue that the chatbot's response still makes sense, as it identifies holders who have ever processed the token, regardless of whether they still hold it or not.
To obtain the information intended by the reference dashboard, we modified the question:
Prompt B: PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', how many users hold current balance on this token and what is the average balance that one user owns?
The chatbot's response was different this time:

Upon examination, we found that the chatbot correctly switched to the appropriate table and generated the following SQL query:
SELECT COUNT(DISTINCT user_address) AS num_users,
AVG(current_bal) AS avg_balance
FROM ethereum.core.ez_current_balances
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
This query provides the accurate number of holders with current balances and the average token balance. It is worth noting that a more reliable method for calculating the average balance would be to use the formula SUM(current_bal)/num_users, as shown in the reference dashboard. However, in this case, the table contains all distinct user_addresses, so using AVG(current_bal) directly is acceptable.
There are alternative ways to phrase the question that could yield the same result. For instance, another prompt we tested that worked is:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the number of holders who still have a current balance and what is the average amount of that balance?
It is essential to remember that the chatbot's responses are not deterministic. Even for prompts that have produced correct results, they could potentially generate different (incorrect) results in other instances, as we have observed. This uncertainty further emphasizes the importance of checking and verifying the actual SQL statements that generate the output.
Token holder groups analysis
The next dashboard items groups the PEPE holders into five bins based their holding amount. We constructed the following prompt to reproduce it:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', among all users who hold current PEPE balances, can you group them according to their balance amount as follows: more than 200 billion, between 50-200 billion, between 10-50 billion PEPE, between 5-10 billion, and less than 5 billion PEPE, to find out what is the number of users in each group?
Here is the result:

The chatbot was able to select the right table and retrieve correct results via the SQL statement as below:
Top token holders analysis
The next item in the dashboard displays the top 10 token holders, we use the following prompt:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the top 10 holders that have the highest current balance of the token?
The GPT produces the result:

with the following SQL query:
SELECT dl.address_name,
ec.current_bal
FROM ethereum.core.ez_current_balances ec
JOIN ethereum.core.dim_labels dl
ON ec.user_address = dl.address
WHERE ec.contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
ORDER BY ec.current_bal DESC
LIMIT 10
The chatbot was not only able to obtain the top 10 token holders from the ez_current_balances table but also map the address to labels using the dim_labels table for easier reading. A small but pleasant surprise!
Token trading volume analysis
The token's trading analysis on the dashboard starts with an hourly trading volume. So we used the following prompt:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the hourly trading volumes of this token?
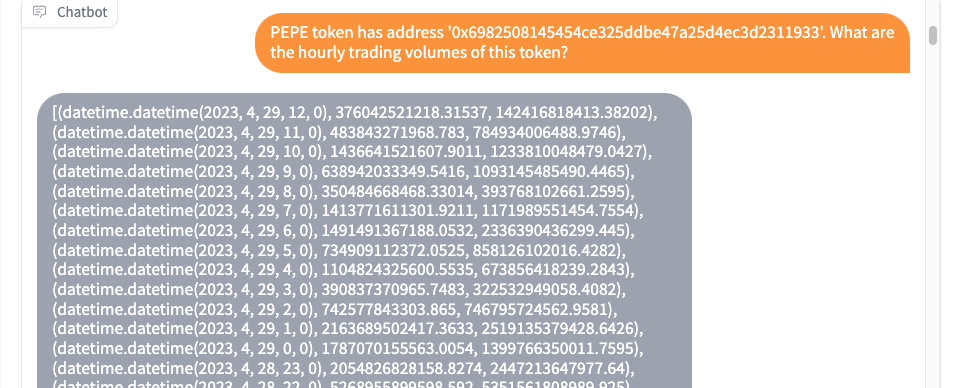
Here is the SQL command it generates:
SELECT date_trunc('hour', block_timestamp) as hour,
SUM(amount_in) as hourly_volume_in,
SUM(amount_out) as hourly_volume_out
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
OR token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hourThe chatbot selects the ez_dex_swaps table, truncates the time to hourly, and counts both amount_in and amount_out in cases where either token_in or token_out involves the PEPE token. Again this seems to be a relevant answer but not what we originally intended. Let's give it a hint to use the ez_token_transfers table instead, as in the reference dashboard.

Looking at the SQL query underneath it, we verified that it now uses the same method as the reference dashboard:
SELECT date_trunc('hour', block_timestamp) as hour,
sum(amount) as hourly_trading_volume
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hour DESCWe can also ask it to produce the amount in USD:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What are the hourly trading volumes in USD of this token? (Use the ethereum.core.ez_token_transfers table)

The chatbot handled it correctly with the following SQL statement:
SELECT date_trunc('hour', block_timestamp) as hour,
sum(amount_usd) as hourly_trading_volume
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY hour ORDER BY hour DESCToken transactions vs. users analysis
The next item is about token transactions per user:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the average hourly trading volume per user of this token? (use the ethereum.core.ez_token_transfers table)

The generated SQL statement is as follows:
SELECT date_trunc('hour', block_timestamp) as hour,
from_address,
sum(amount) as total_volume,
count(distinct from_address) as unique_users,
sum(amount)/count(distinct from_address) as avg_volume_per_user
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY 1, 2 ORDER BY 1 DESCWhen attempting to get the transaction amount in USD per user, the chatbot forgot (or ignored) the overall prompt instruction to check available tables and started creating non-existing tables. So we had to emphasize it again in the question prompt:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the average hourly trading volume in USD per user of this token? (make sure to check available tables and use the ethereum.core.ez_token_transfers table)
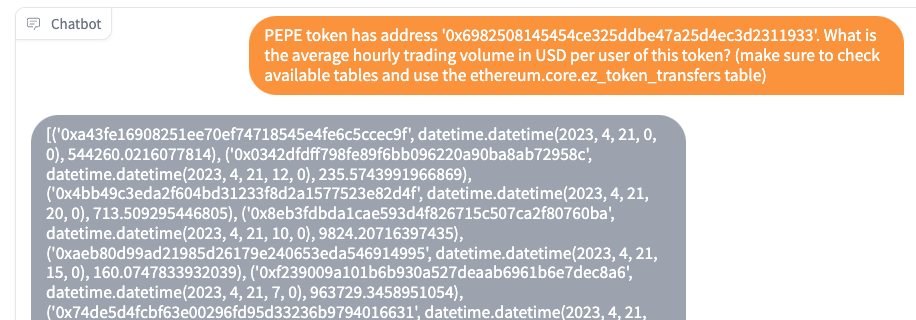
This time, the results are not sorted in descending order, but the overall query logic is still correct.
SELECT from_address,
date_trunc('hour', block_timestamp) as hour,
sum(amount_usd) / count(distinct from_address) as avg_hourly_trading_volume_per_user
FROM ethereum.core.ez_token_transfers
WHERE contract_address = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY 1, 2Token "Swapping in" and "Swapping out" analysis
The dashboard also analyzed the swapping in and out of the token. Let's try it with ChatWeb3:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of swap in and swap out counts for this token and their total amount in USD?
This time the GPT again bypassed our instruction to check the available tables and start to "invent" commands, and it even mentions about using Uniswap V2 subgraph (which is never mentioned in the prompt), below is a snippet of its thought process:
Thought: We need to find the number of swap in and swap out counts for the PEPE token and their total amount in USD. We can use the Uniswap V2 subgraph to get this information.\n\nAction:\n```\n{\n "action": "query_snowflake_database",\n "action_input": {\n "query": "SELECT COUNT() AS swap_in_count, SUM(amountUSD) AS swap_in_amount, (SELECT COUNT() FROM uniswap_v2."swap" WHERE token0 = '0x6982508145454ce325ddbe47a25d4ec3d2311933' OR token1 = '0x6982508145454ce325ddbe47a25d4ec3d2311933') - COUNT(*) AS swap_out_count, (SELECT SUM(amountUSD) FROM uniswap_v2."swap" WHERE token0 = '0x6982508145454ce325ddbe47a25d4ec3d2311933' OR token1 = '0x6982508145454ce325ddbe47a25d4ec3d2311933') - SUM(amountUSD) AS swap_out_amount FROM uniswap_v2."swap" WHERE token0' ...
To bring GPT back to reality, we asked it again to follow the proper tools and sequences:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of swap in and swap out counts for this token and their total amount in USD? (please make sure to check available tables and only use the available tools)
Now it produces the following result:

Let's check the SQL query to see whether it is valid:
SELECT COUNT(*) AS swap_in_count,
SUM(amount_in_usd) AS total_amount_in_usd,
COUNT(*) AS swap_out_count,
SUM(amount_out_usd) AS total_amount_out_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
OR token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'Well, it appears to have mixed up swap in and swap out together, which wasn't what we wanted. To be fair, the question prompt wasn't super clear, even if given to a human. After a few trials, we found that the following prompt produced the same result as the reference dashboard:
'PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933'. What is the number of distinct swap transactions and user addresses where this token is swapped in and what is the total USD amount?

We verified the GPT-generated SQL query:
SELECT COUNT(DISTINCT tx_hash) AS num_transactions,
COUNT(DISTINCT origin_from_address) AS num_addresses,
SUM(amount_in_usd) AS total_usd_amount
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'Similarly, we were able to obtain the Swap Out side of the amount using an appropriate prompt.

The GPT-generated SQL query was also verified:
SELECT COUNT(DISTINCT tx_hash) AS num_swap_transactions,
COUNT(DISTINCT tx_to) AS num_user_addresses,
SUM(amount_out_usd) AS total_usd_amount
FROM ethereum.core.ez_dex_swaps
WHERE token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'Token "swapping to" and "swapping from" analysis
The last part of the dashboard looked at the top tokens that are swapped to and from PEPE. Let's see what our ChatWeb3 finds out:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out what are the top 10 tokens it has been swapped to most?

Looking at the underlying SQL, it was counting the number of swaps:
SELECT symbol_out, COUNT(*) AS swap_count
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY symbol_out ORDER BY swap_count DESC
LIMIT 10But the reference dashboard was actually counting the amount in USD, so we refined the prompt:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out what are the 5 tokens that it has been swapped to most in terms of amount in USD?
However, it found nothing!

Why? Let's look at the SQL statement it generated:
SELECT token_out,
SUM(amount_out_usd) AS total_amount_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY token_out ORDER BY total_amount_usd DESC
LIMIT 5
We realized that the query seemed to be correct and eventually found out a possible explanation from the ez_dex_swaps table's comment:
Note: A rule has been put in place to null out the amount_USD if that number is too divergent between amount_in_USD and amount_out_usd. This can happen for swaps of less liquid tokens during very high fluctuation of price.
Given that this was a highly illiquid token, it was likely the relevant amount_USD field had been nulled out. The reference dashboard used amount_in_usd, so let's gave GPT a hint:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find out the top 5 tokens that it has been swapped to measured in the USD amount of input tokens? (make sure to produce concise thoughts and generate appropriate tool inputs)
Note that we added another part of explicit reminder prompt asking it to produce concise thoughts and generate appropriate tool inputs. This is because it starts to become overly talkative and produces longer thoughts in the intermediate steps that causes error due to prompt window size limits.

At least this time it produces the intended results, as confirmed by the underlying SQL statement:
SELECT symbol_out,
SUM(amount_in_usd) AS total_input_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
AND amount_in_usd IS NOT NULL
GROUP BY symbol_out ORDER BY total_input_usd DESC
LIMIT 5Now let's look at the the reverse side of the swap:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', can you find the top 5 token symbols that have been swapped into PEPE most and order them by their USD amount? (make sure to produce concise thoughts and generate appropriate tool inputs)

But it kept getting the "swap" side wrong, and was still selecting the output token.
SELECT symbol_out,
SUM(amount_out_usd) AS total_amount_usd
FROM ethereum.core.ez_dex_swaps
WHERE token_in = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY symbol_out ORDER BY total_amount_usd DESC
LIMIT 5After we give it more explicit hint to check your token input vs. output selection:
PEPE token has address '0x6982508145454ce325ddbe47a25d4ec3d2311933', Find the 5 top token symbols that have been swapped into PEPE, and order them by the swap amount in USD? (make sure to check your token input vs. output selection)
It finally produces the correct result:

Which was verified to be from the correct SQL statement:
SELECT token_in,
SUM(amount_out_usd) AS total_usd_value
FROM ethereum.core.ez_dex_swaps
WHERE token_out = '0x6982508145454ce325ddbe47a25d4ec3d2311933'
GROUP BY token_in ORDER BY total_usd_value DESC
LIMIT 5
Lessons learned, challenges and discussions
The primary challenges encountered during this project include GPT prompt size constraints, the non-deterministic nature of the responses, and reasoning and instruction-following.
Prompt size constraints
The 4K prompt size window of the GPT-3.5-turbo model presents several limitations, affecting table selection and the number of iterations during the query process.
Table indexing scaling and optimization
The prompt size limits the number of tables and their respective information we can present to GPT. Several potential solutions to scale it are:
- Horizontal scaling: Splitting table information content into multiple parts and submitting them through separate queries.
- Vertical scaling: Using newer GPT models, like GPT-4, which offer larger prompt windows (8K and 32K) but come with higher costs.
- Off-loading: Storing table metadata in a vector store index and using semantic search for table selection.
Metadata optimization can also enhance GPT's relevance in decision-making. Currently, we use existing table comments and sample row values, but expanding the metadata scope is possible. For instance, including more database models details can help GPT understand the structure and relationships of tables and views.
Iteration Steps
The prompt size limit affects the number of iterations that can be run during the query process. In the current implementation, all the intermediary steps' observations are accumulated to the prompt, causing it to fill up pretty quickly. The system needs improvement to address these issues by creating more atomic and modular steps that are prompt-size friendly while preserving the continuity of the thought process.
Non-deterministic Nature of GPT Responses
GPT's non-deterministic nature means that it may produce different results in different runs, even with "good" prompts. This necessitates the verification of underlying SQL statements, which offsets the benefit of "not requiring SQL skills." A few related issues observed include:
Maximum length of GPT output:
Unexpectedly, the max_tokens parameter setting of the GPT model can cause issues. This parameter designates the maximum number of language tokens the model should generate and it is part of the prompt window. We set it to 256 (of the total 4K prompt size) because we want to leave enough space for inputs such as database table information. We also tried relaxing the limit and see what happens. If we set it to 1K or even unlimited, GPT becomes overly talkative in its thoughts. But what is problematic is, the longer thoughts are accompanied by complicating solutions for simple questions. E.g., it would create many join statements for tables and columns that never exist. In a sense, giving it more room to think make the the performance 'worse'! Even with our explicit maximum token limit, it still sometimes run over the 256 limit. This causes error because the program will forcefully return only the first 256 language tokens generated, and the rest of the program cannot parse that incomplete response. In these situations, explicitly reminding the GPT in the question prompt such as "make sure to produce concise thoughts" usually mitigates the problem.
Reasoning and instruction following
GPT demonstrates strong reasoning capabilities but produces flawed results from time to time. Its non-deterministic nature can cause it to follow instructions (e.g., check available tables, get table metadata before constructing queries) better at times and worse at others. Simple reminders in question prompts can usually bring it back to a normal state. Newer models, like GPT-4, are known to follow system category instructions more strictly, which hopefully will alleviate this issue.
Opportunities, next steps and future work
Despite the limitations of the current system, there are numerous ways to enhance its capabilities and make it more useful for blockchain data analysis.
Conversational memory and co-pilot mode
GPT, in its current state, may be better suited as a co-pilot or assistant to users who can at least verify SQL statements while exploring large databases. By enabling conversational memory, users can maintain a longer dialogue and provide more guidance as they uncover new information. This approach also addresses the prompt size limitation issue to some extent, enabling deeper use cases with ChatWeb3.
Table index scaling and multi-chain capability
ChatWeb3 is designed to be multi-chain ready, capable of incorporating tables from different databases representing various chains. By applying the scaling solutions mentioned previously to table indexing, the system can be immediately adapted for cross-chain analysis.
Leveraging Auto-GPT/Baby-AGI
Exploring the use of Auto-GPT and Baby-AGI for analysis tasks is another exciting prospect. Instead of focusing on confirmatory tasks, GPT could be given objectives and allowed to decide which tables, columns, and information are useful for generating insightful analyses. This approach capitalizes on GPT's generative strengths.
Alternative approaches
The current method of using GPT's text-to-SQL capability for chat-based blockchain database queries is not the only way to integrate AI and blockchain data analysis. Some other possibilities include:
- Customizing models for the blockchain domain: Fine-tuning existing models or training new models specifically for blockchain data could lead to more effective solutions.
- Exploring different data formats: Rather than limiting the model to processing SQL database format information, training it with raw blockchain records could yield alternative solutions.
- Integrating ChatGPT with other APIs: Connecting ChatGPT with various APIs designed to facilitate blockchain data analysis could expand its capabilities and enable more comprehensive insights.
Conclusions
Leveraging ChatGPT's text-to-SQL capability to make blockchain data analysis accessible to all is an ambitious vision. In this article, we introduced ChatWeb3, a prototype built using ChatGPT, Langchain, and Flipsidecrypto, which enables users to "chat" with a blockchain database. Our preliminary experiments revealed numerous challenges rooted from factors such as the non-deterministic nature of GPT responses and prompt window constraints, indicating that the current system isn't quite ready for a fully autonomous experience. However, it provides a glimpse into a more accessible future for blockchain data analytics.
By enhancing the system with conversational memory, table index scaling and optimization, auto-GPT/baby-AGI capability, and alternative AI approaches, we can move closer to democratizing blockchain data analysis for a wider audience. As AI continues to evolve, the integration of ChatGPT and similar large language models into blockchain data analysis tools will likely become more seamless, unlocking these technologies' full potential for the masses.
The code of this prototype is Open Source and available at https://github.com/inWeb3ai/chatWeb3. If you're interested in learning more, please follow us on Twitter and subscribe (for free) to inWeb3 to stay updated. Thank you!